

Background
I am again this year teaching a small group learning course on critical appraisal for MPH students using a unique format. Each group is divided into three smaller subgroups of four or five students. The first subgroup received only an introduction to the problem, and without looking at the chosen article, discusses their choice of study design to address the problem. The second subgroup received only the published abstract and comments on what details they would expect to see in the full article. The third subgroup read the whole article and in addition to highlighting its strengths and limitations tried to answer queries raised by the first 2 groups. The goal is to not only improve critical appraisal skills but also to think about research questions, designs and the necessary compromises that are often required in research. Hopefully this adds another dimension to typical journal clubs where either an article in uncritically endorsed enthusiastically or trashed unmercifully.
One of the articles was this 2016 JAMA article was a systematic review of the prevalence of depression or depressive symptoms among medical students. The data were extracted from 167 cross-sectional studies (n=116628) and 16 longitudinal studies (n=5728) from 43 countries. The authors state they followed the Preferred Reporting Items for Systematic Reviews andMeta-analyses and Meta-analysis of Observational Studies in Epidemiology reporting guidelines. They reported overall pooled crude prevalence of depression or depressive symptoms was 27.2% (37933/122356 individuals; 95% CI, 24.7% to 29.9%, \(I^2\)=98.9%) and concluded the following
Leaving aside some contextual issues such as
- the reliability of self reporting as opposed to a structured diagnostic interview
- the ability of screening tools to accurately diagnosis depression (low positive predictive values)
I think it is important to take the time to reflect on the statistical models and their proper interpretation.
Statistical models in meta-analysis
The authors reported using a random effects model. What does this mean and what the implications?
A meta-analysis is actually nothing more than a mixed model, which is itself an extension of simple regression model that contains both explained (fixed) and unexplained (random) elements through the use of variance components.
First the fixed effect, where the variance is the sampling variance for each study where the studies are assumed to all arise from one common distribution. Graphically, this is displayed as follows where the distribution remains centered for each study and its spread it determined by the respective variances.
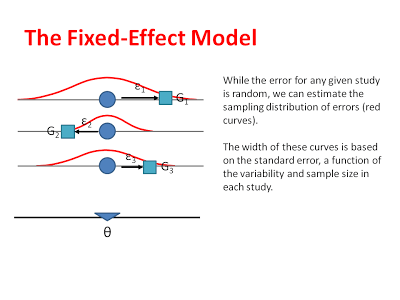
A typically more realistic random effects model considers not only this within sample variation but acknowledges it is unlikely that individual studies are identical and consequently also exhibit between study variation, as measured by the \(I^2\) statistic, as shown below
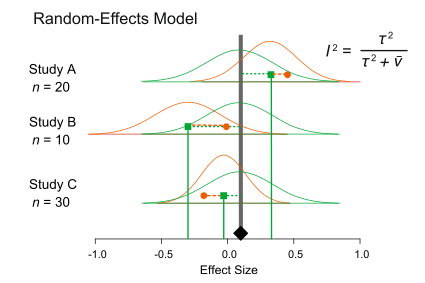
IOW, the individual studies may be considered as drawn from a supra-population distribution of potential studies, as indicated by the green curve above and blue curve below
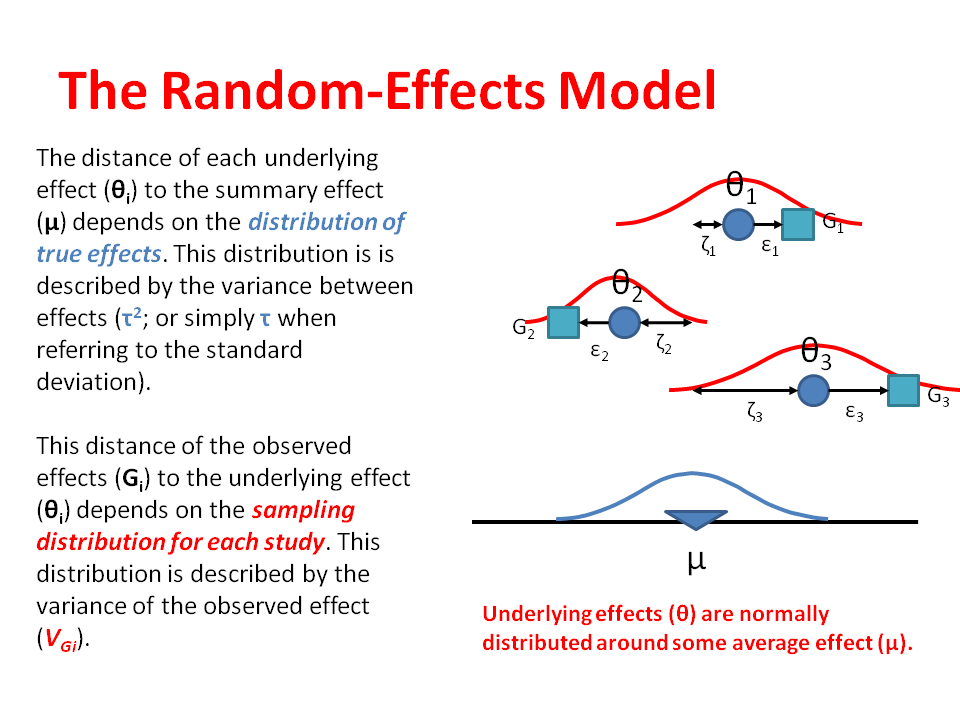
Return to the JAMA article
Recall the results of an overall pooled crude prevalence of depression or depressive symptoms was 27.2% (37933/122356 individuals; 95% CI, 24.7% to 29.9%, \(I^2\)=98.9%).
Some general caveats
A rough guide to \(I^2\) interpretations is as follows:
0% to 40%: might not be important;
30% to 60%: may represent moderate heterogeneity
50% to 90%: may represent substantial heterogeneity
75% to 100%: considerable heterogeneity
What does this mean?
It means if we are combining studies to compare apples to oranges and start including studies that are comparing apples to bananas, apples to grapes and oranges to pineapples, etc we are to end up with a fruit salad rather than an understanding of the original comparison being sought (leaving aside the possibility of performing a network meta-analysis). Even if only apple versus orange studies are included, if they are of poor quality where perhaps the “appleness” or “orangeness” has been poorly measured we are unlikely to get reliable results. Summarizing,
- GIGO (garbage in - garbage out)
- excessive unexplained heterogeneity = fruit salad
Analyses
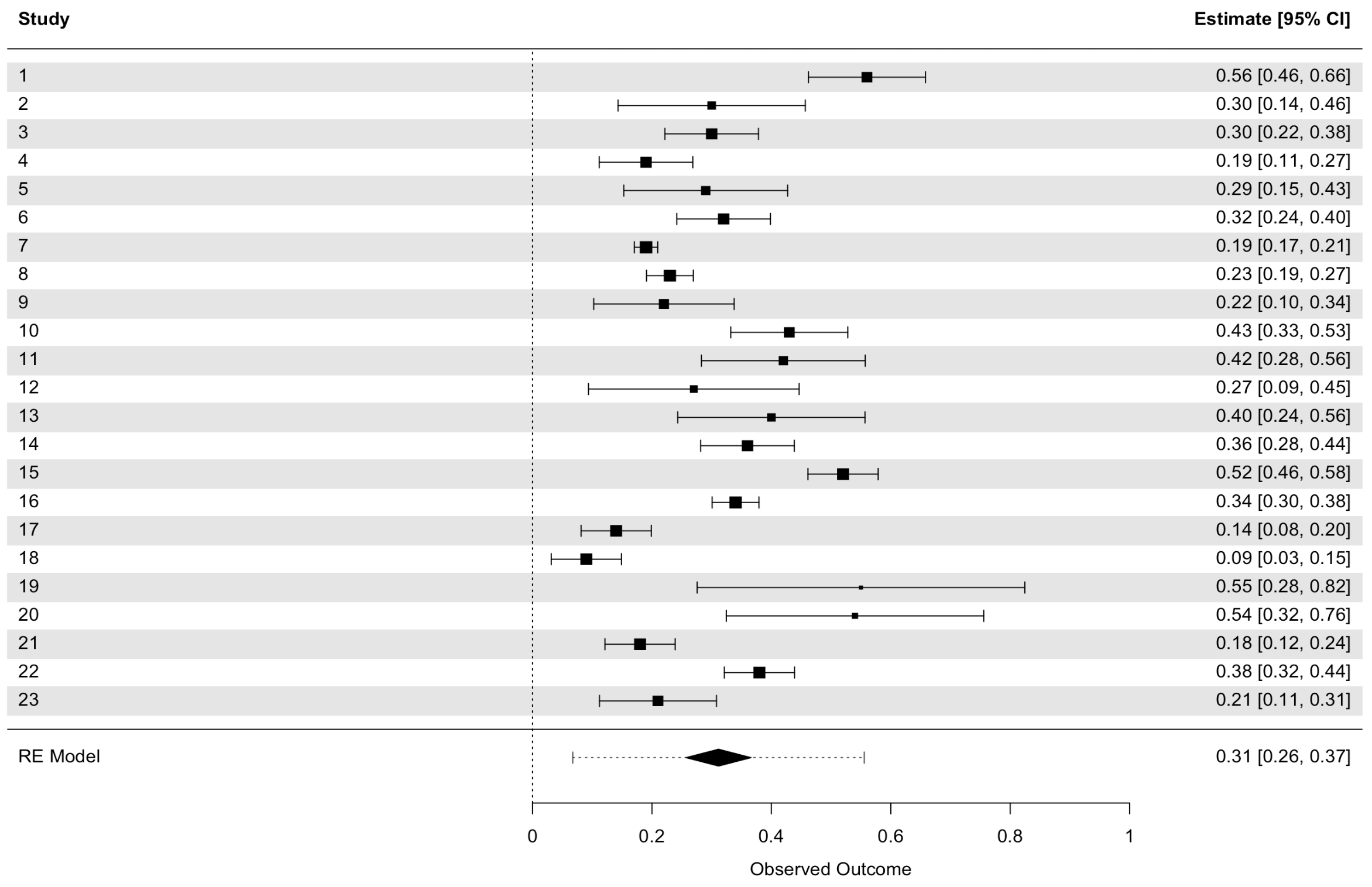
Consider their Figure 7 (chosen since the 183 studies have been grouped into 23 groups making data extraction more manageable).
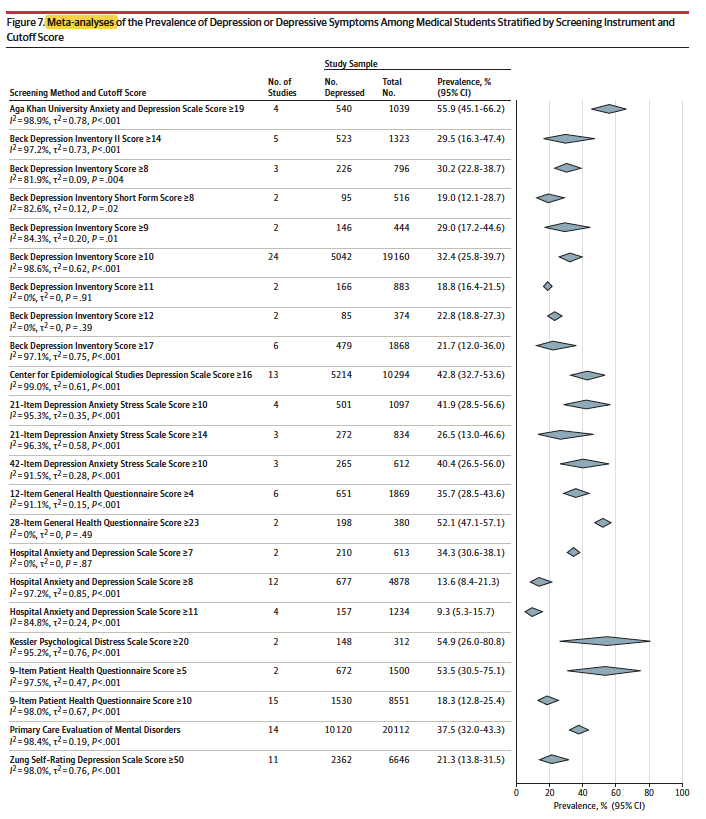
Question: Does this Figure represent a meta-analysis?
Answer: Given that a meta-analysis is the statistical combination of the results of multiple studies to quantify the effect size across all of the studies, and given its absence (as well as any measure of the combined variation), it is hard to label this Figure a meta-analysis.
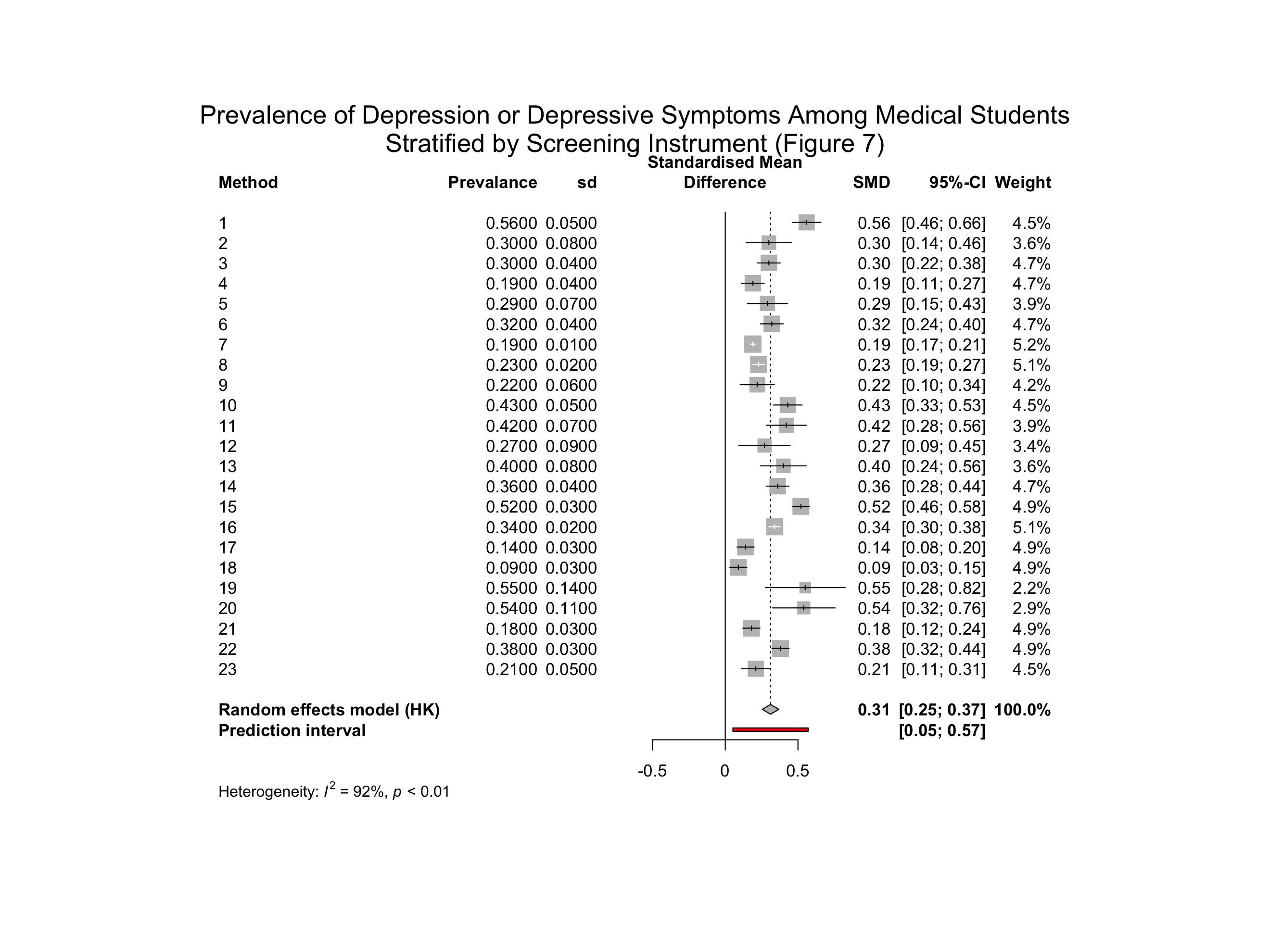
Here is a Figure that does include the desired measures.
The combined effect shows a results that is comparable with the reported depression prevalence of 27.2% (95% CI, 24.7% to 29.9%) with the difference due to the original analysis not grouping the 183 studies.
Question: What is the dotted line and what does it represent?
Answer: This is known as the prediction interval. Remember that in a random effects model the studies come from an over-riding population distribution and the 95% CI of this distribution is the prediction interval. Therefore the next study would come from a draw from this distribution and NOT from a draw of distribution of the mean effect shown in the line above.
Question: What is probability of the prevalence of depression in the next study (or in your medical school)?
Answer: Although 95% CI are often interpreted as probability intervals, this is actually incorrect. To obtain probability statements one needs to switch to a Bayesian paradigm. This is beyond the scope of this presentation but fortunately, given the large amount of available data, little error is introduced by not doing the formal Bayesian analysis. This is shown by the figure below, produced by a Bayesian analysis with vague priors, which gives essential the same result as the frequentist analysis.
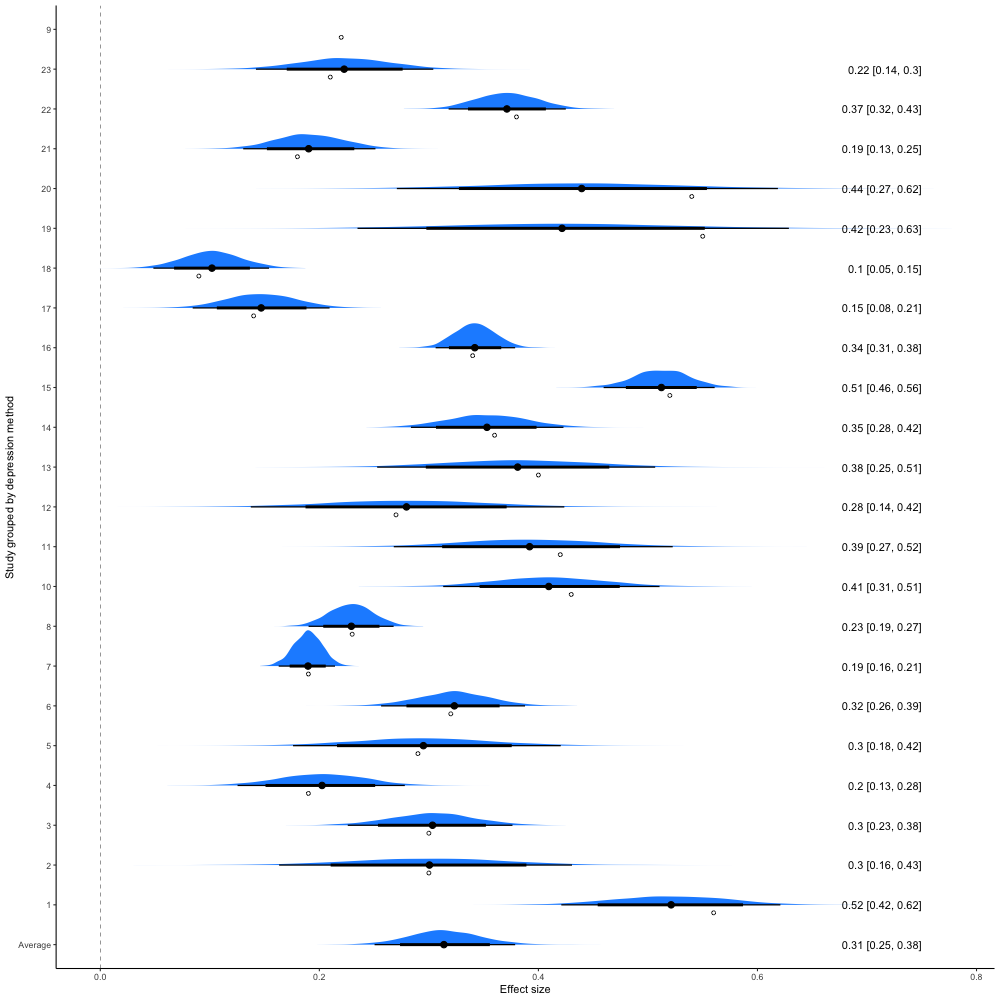
The blue areas represent the probability distributions and the thin and thick black lines the 80% and 95% credible intervals (CrI). The mean and 95% CrI are 0.314, 0.250 - 0.379, very close to the previous confidence intervals.
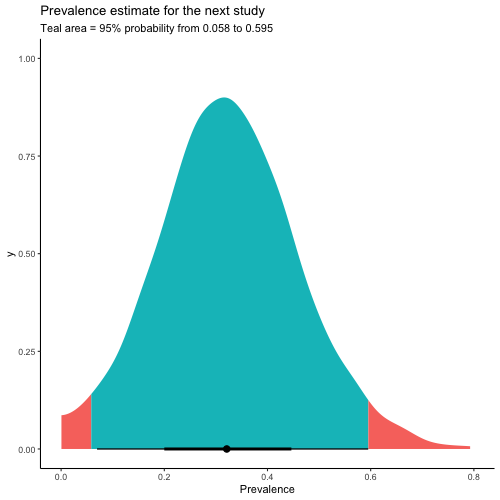
Since we are interested in the next study we need the prediction interval distribution which follows
Conclusions
What to think about the authors’ conclusion “the prevalence of depression among medical students is 27%”?
Ignoring the non-trivial limitations of depression screening tools as diagnostic tools and the lack of validity for self administration, a proper understanding of the statistical model suggests that this meta-analysis of these diverse publications reveals the next study is likely to show at least some medical students have depressive symptoms but this is likely less than 75%!
IOW, this study is not very informative and its implied precision is a misrepresentation.
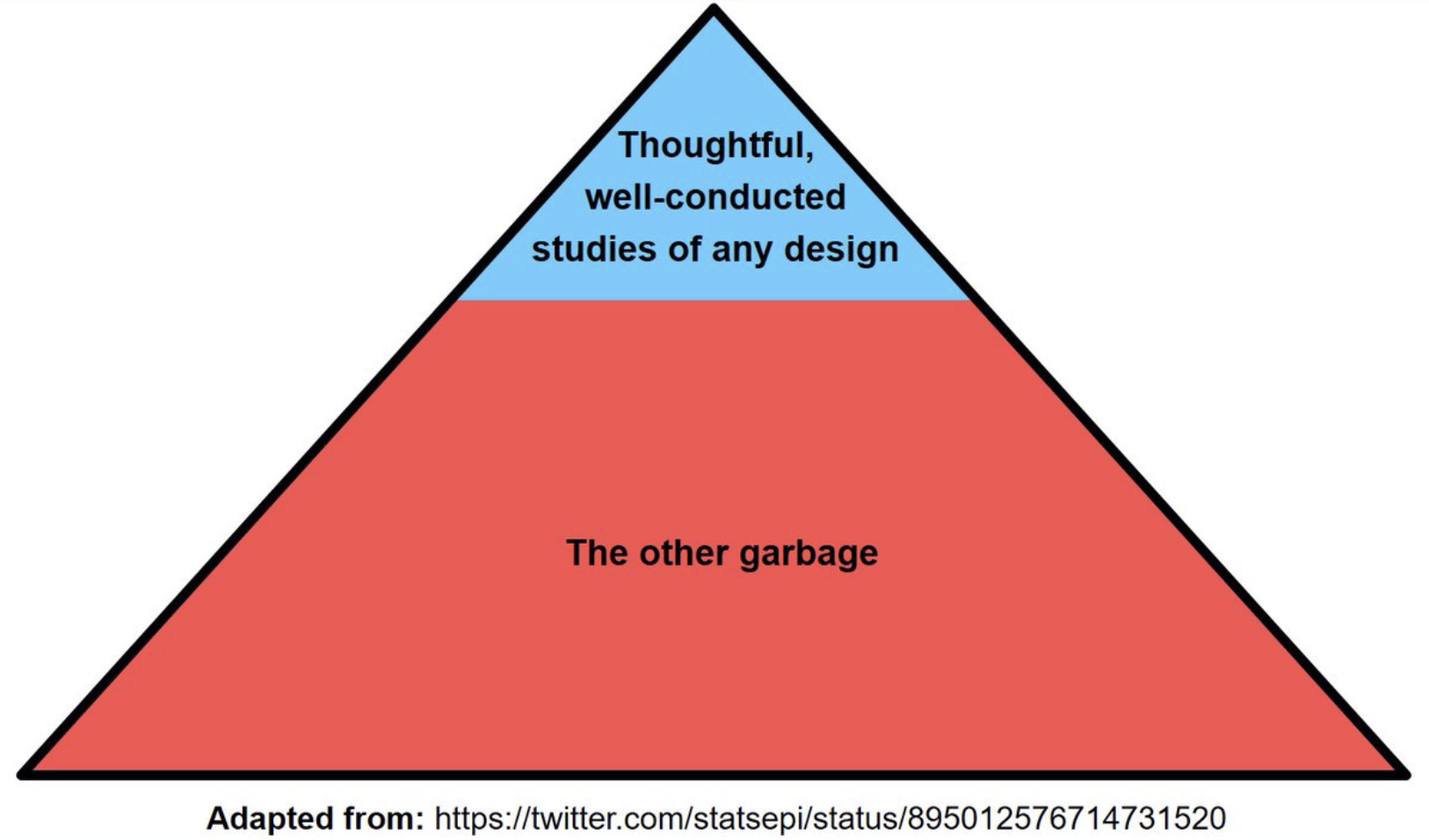
Caveat lector
Figure on the top is often presented but figure on the bottom better reflects reality

Citation
BibTeX citation:
@online{brophy2024,
author = {Brophy, Jay},
title = {What Is the Prevalence of Depression in Medical Students?},
date = {2024-02-05},
url = {https://brophyj.github.io/posts/2024-02-05-my-blog-post/},
langid = {en}
}
For attribution, please cite this work as:
Brophy, Jay. 2024. “What Is the Prevalence of Depression in
Medical Students?” February 5, 2024. https://brophyj.github.io/posts/2024-02-05-my-blog-post/.