I recently read an article entitled “One-Year Outcomes of Transseptal Mitral Valvein- Valve in Intermediate Surgical Risk Patients”(Malaisrie et al. 2024)paper. After examining 50 patients from 12 sites that underwent mitral valve-in-valve from 2018 to 2021 the authors concluded
“Mitral valve-in-valve with a balloon-expandable valve via transseptal approach in intermediate-risk patients was associated with improved symptoms and quality of life, adequate transcatheter valve performance, and no mortality or stroke at 1-year follow-up.”
This prompted me to wonder how probable would it be to observe 0 deaths in the 50 patients at 1 year if the annual transcather mitral valve mortality was actually the same as their expected value with a surgical redo, 4%. I also wondered how well my colleagues would estimate this uncertainty (probability) and therefore created and circulated the following short questionnaire.
Quiz
A recent study reported no mortality in 50 patients undergoing transcatheter mitral valve-in-valve replacement (MVIV) for patients with bioprosthetic valve failure. The STS mortality score for these patients undergoing a standard redo operation is an estimated 4%.
Q1. If mortality rates with transcatheter MVIV are assumed the same as with a standard redo, what is the probability of observing 0 deaths as these authors did?
<1%
1 - 4.9%
5 -9.9%
10 - 14.9%
> 15%
Q2. If mortality rates with transcatheter MVIV were actually 40% higher those with a standard redo, what is the probability of observing 0 deaths as these authors did?
<1%
1 - 4.9%
5 -9.9%
10 - 14.9%
> 15%
Q3. Given the above information (and that there is probably not a lot of other of good quality available evidence), what is your probability (belief) that MVIV is as safe or safer than a standard redo operation in this population?
< 25 %
25 - 50%
51 - 75%
76 - 95%
> 95%
Basic Probability Distributions
Answering these questions, requires making some assumptions about possible models, in other words underlying probability distributions, that could represent the data. Here are some of the more common probability distributions and their utility according to the available data.
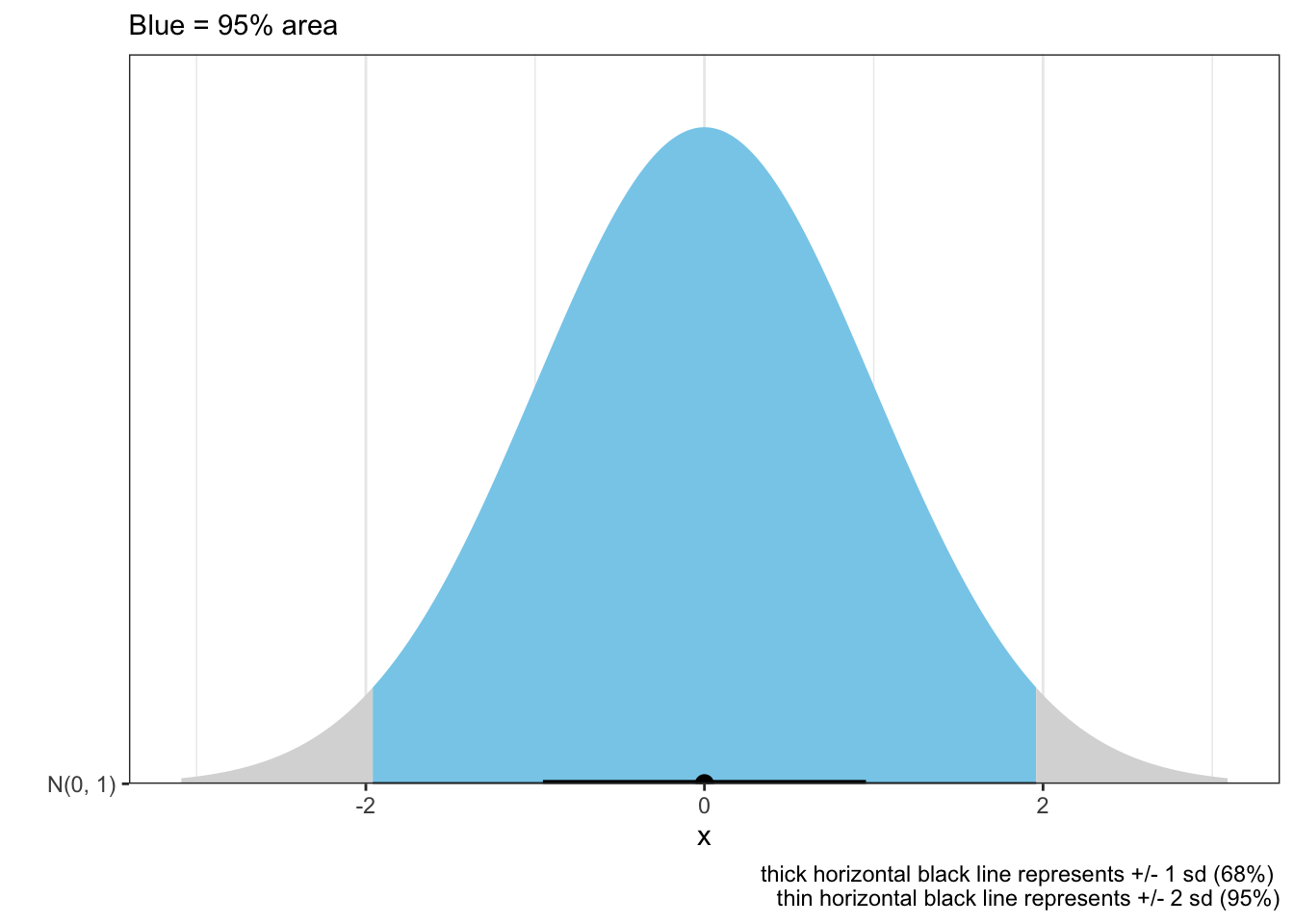
Normal distribution
Normal distributions are ubiquitous and generally reasonably well understood. They are important in medicine, at least partly due to the central limit theorem that states under some conditions, the average of many samples (observations) of a random variable with finite mean and variance is itself a random variable—whose distribution converges to a normal distribution as the number of samples increases. Therefore, physical quantities that are expected to be the sum of many independent processes, such as measurement errors, often have distributions that are nearly normal.
Mathematically the normal distribution is expressed as \[f(x) = \frac{1}{\sqrt{2 \pi \sigma^2}} e^{-\frac{(x-\mu)^2}{2 \sigma^2}}\]
where \({\mu}\) is the mean or expectation of the distribution (and also its median and mode)
\({\sigma^{2}}\) is the variance and
\({\sigma }\) is the standard deviation of the distribution
Graphically this may be plotted as shown
Code
n_dis=tibble(dist =c(dist_normal(0, 1)))n_dis%>%ggplot(aes(y =format(dist), xdist =dist))+stat_halfeye(aes(fill =after_stat(abs(x)<1.96)))+labs(ggtitle="Normal (0,1) distribution", subtitle="Blue = 95% area", caption ="thick horizontal black line represents +/- 1 sd (68%) \nthin horizontal black line represents +/- 2 sd (95%)")+scale_fill_manual(values =c("gray85", "skyblue"))+scale_y_discrete(expand =c(0, 0, 0, 1))+ylab("")+theme_bw()+theme(legend.position="none")
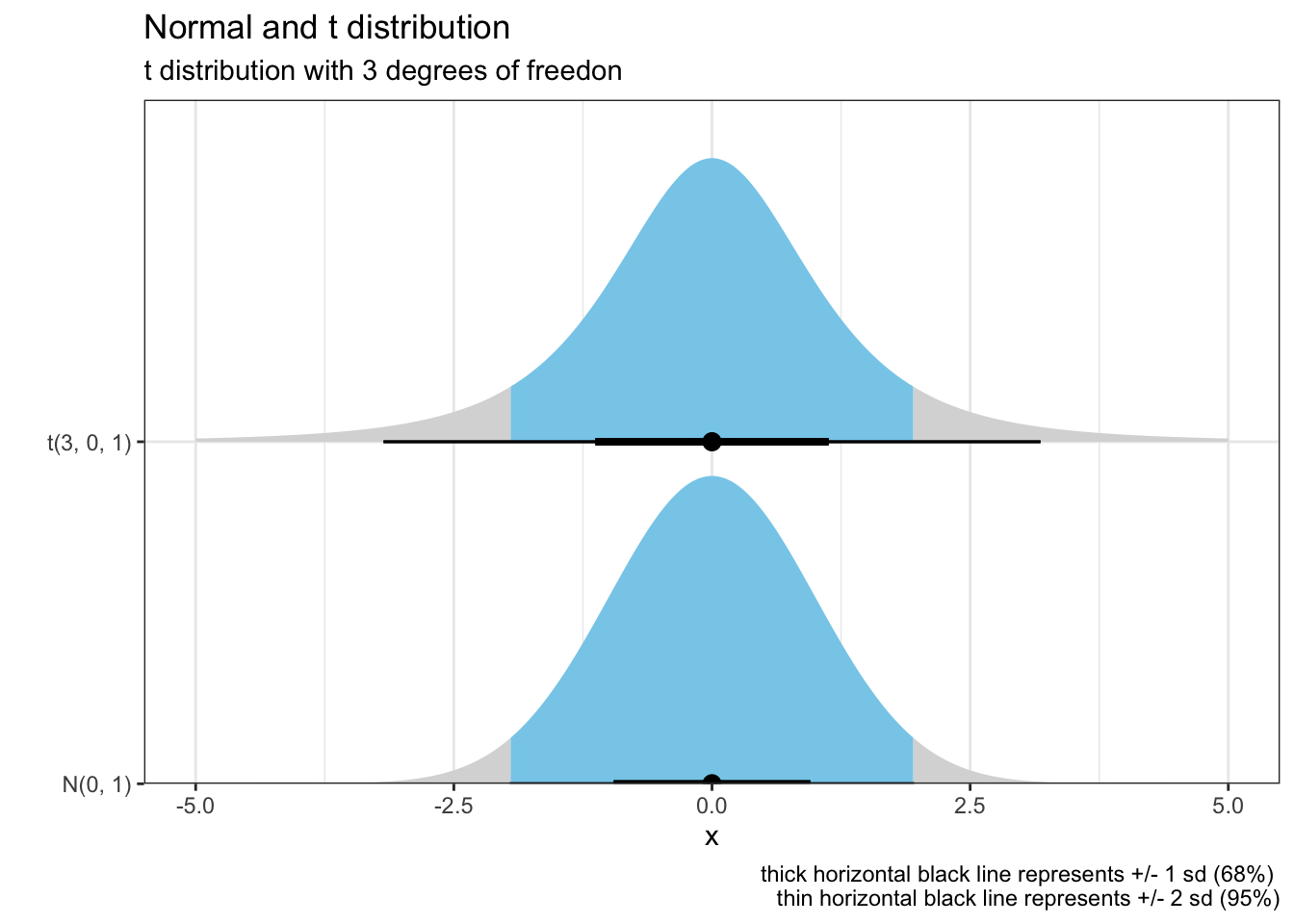
Student’s t distribution
The Student’s t distribution is another continuous probability distribution that generalizes the standard normal distribution, remaining symmetric around zero and bell-shaped but with heavier tails. The amount of probability mass in the tails is controlled by the parameter \({\nu}\). For \({\nu = 1}\) the Student’s t distribution becomes the standard Cauchy distribution, which has very “fat” tails; whereas for \({\nu = \infty}\) it becomes the standard normal distribution
Code
n_t_dis=tibble( dist =c(dist_normal(0, 1), dist_student_t(3, 0, 1)))n_t_dis%>%ggplot(aes(y =format(dist), xdist =dist))+stat_halfeye(aes(fill =after_stat(abs(x)<1.96)))+labs(title="Normal and t distribution", subtitle ="t distribution with 3 degrees of freedon", caption ="thick horizontal black line represents +/- 1 sd (68%) \nthin horizontal black line represents +/- 2 sd (95%)")+scale_fill_manual(values =c("gray85", "skyblue"))+xlim(-5,5)+scale_y_discrete(expand =c(0, 0, 0, 1))+ylab("")+theme_bw()+theme(legend.position="none")
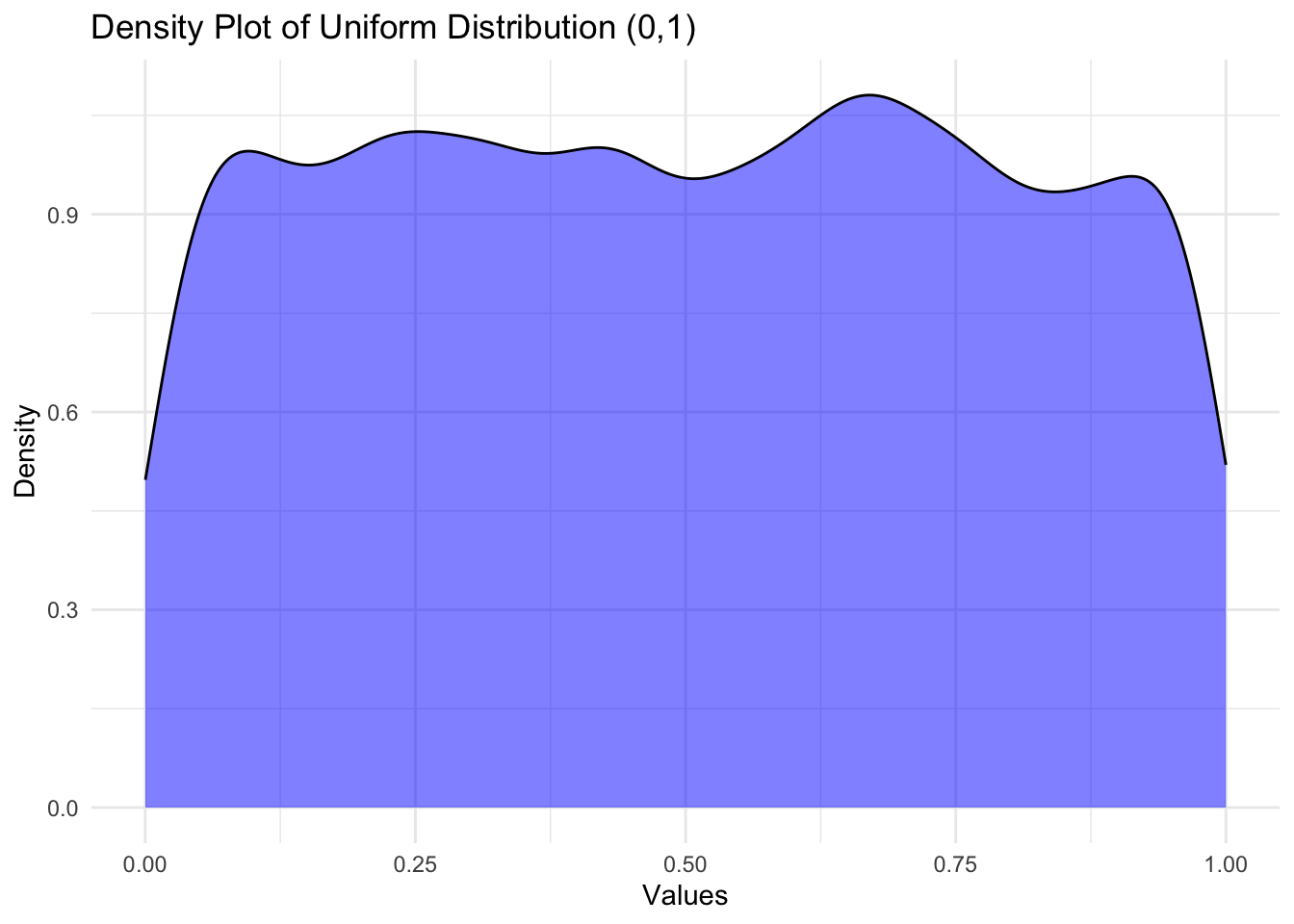
Uniform distribution
The uniform distribution assumes that all continuous outcomes between boundaries have an equal probability of occurring.
Graphically,
Code
# Create a density plot using ggplot2ggplot(data.frame(Values =runif(10000, min =0, max =1)), aes(x =Values))+geom_density(fill ="blue", alpha =0.5)+labs(title ="Density Plot of Uniform Distribution (0,1)", x ="Values", y ="Density")+theme_minimal()
Binomial Distribution
However for this quiz, the data are not continuous but discrete with counts and therefore the above distributions would be inappropriate models (cf negative counts being impossible). A binomial distribution is a discrete probability distribution that describes the number of successes in a fixed number of independent Bernoulli trials, where each trial has the same probability of success, denoted by p. The distribution is characterized by two parameters: n the number of trials, and p, the probability of success in each trial.
Mathematically, this can be expressed as \[P(X = k) = {n \choose x} * p^k * (1 - p)^{n-k}\] • P(X=k) is the probability of having k successes in n trials
• (nCk) is the binomial coefficient, also known as “n choose k”, which represents the number of ways to choose k successes from n trials
• p is the probability of success in each trial
• 1-p is the probability of failure in each trial
• n is the total number of trials
• k is the number of successes
Binomial distributions are commonly used to model situations such as coin flips, where there are two possible outcomes (success or failure) and each trial is independent of the others. They have obviously applications in various fields, including medicine.
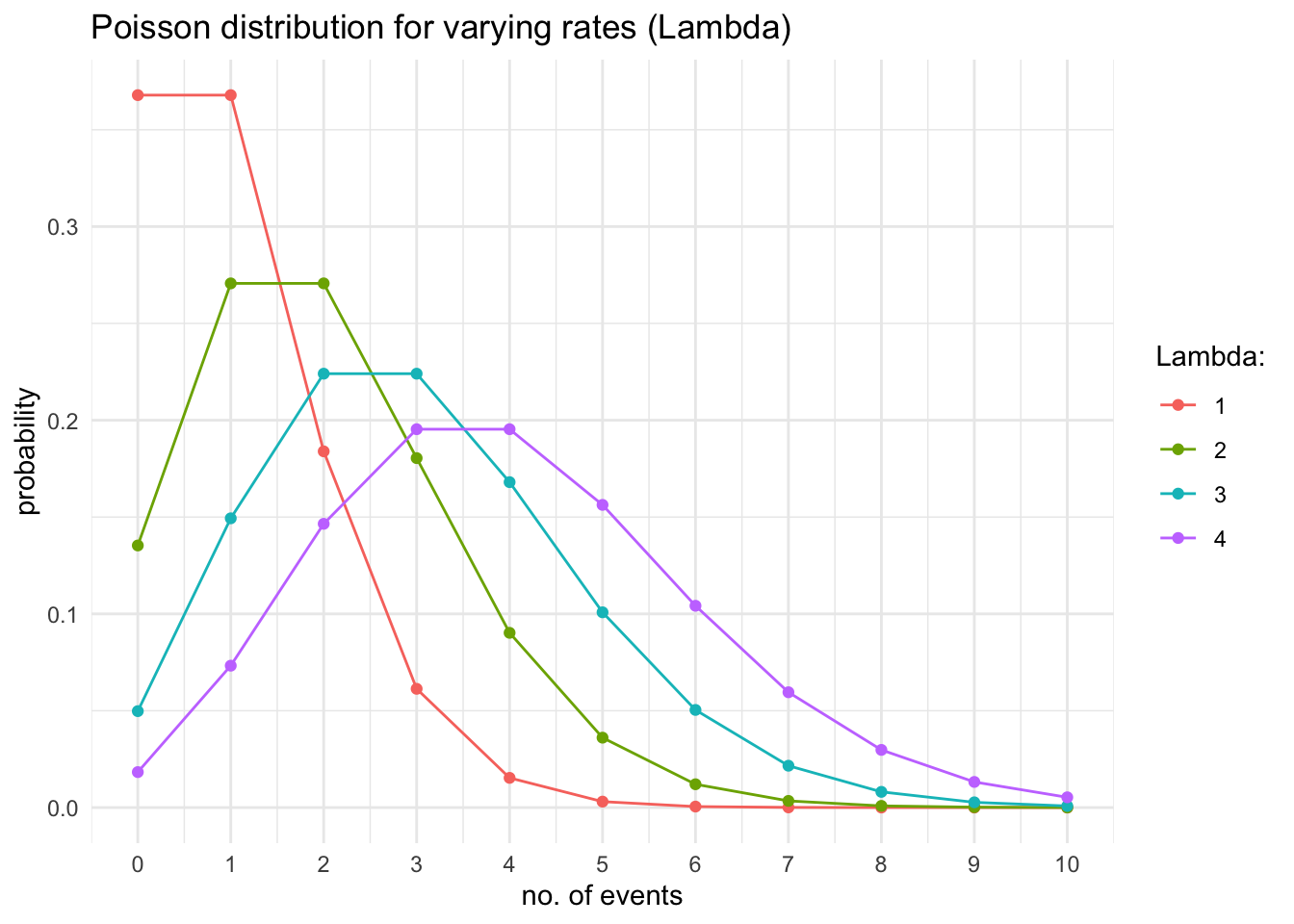
Poisson Distribution
The Poisson distribution is a discrete probability distribution that represents the number of events occurring in a fixed interval of time or space, given that these events occur with a constant rate and independently of the time since the last event. It is named after the French mathematician Siméon Denis Poisson.
Mathematically this can be expressed as
\[P(X = k) = \frac{\lambda^k * e^{-\lambda}}{k!}\] • P(X=k) is the probability of observing k events in a given period of time
• \(\lambda\) is the expectation of the events over the same period of time
For a Poisson random variable, the variance = mean = E(Y) = $ The Poisson distribution is a special case of the binomial, with trials n -> \(\infty\) and p (any trial success) -> 0
If p is small, binomial P(k successes) \(\approx\) poisson P(k with \(\lambda\) = np)
The Poisson distribution is perhaps better appreciated by plotting the above equation
Code
# Build Poisson distributionsoptions(digits =3)p_dat<-map_df(1:4, ~tibble( l =paste(.), x =0:10, y =dpois(0:10, .)))# Use ggplot2 to plotggplot(p_dat, aes(x, y, color =factor(l, levels =1:5)))+geom_line()+geom_point(data =p_dat, aes(x, y, color =factor(l, levels =1:5)))+labs(color ="Lambda:")+ggtitle("Poisson distribution for varying rates (Lambda)")+scale_x_continuous("no. of events",breaks=seq(0,10, 1))+ylab("probability")+theme_minimal()
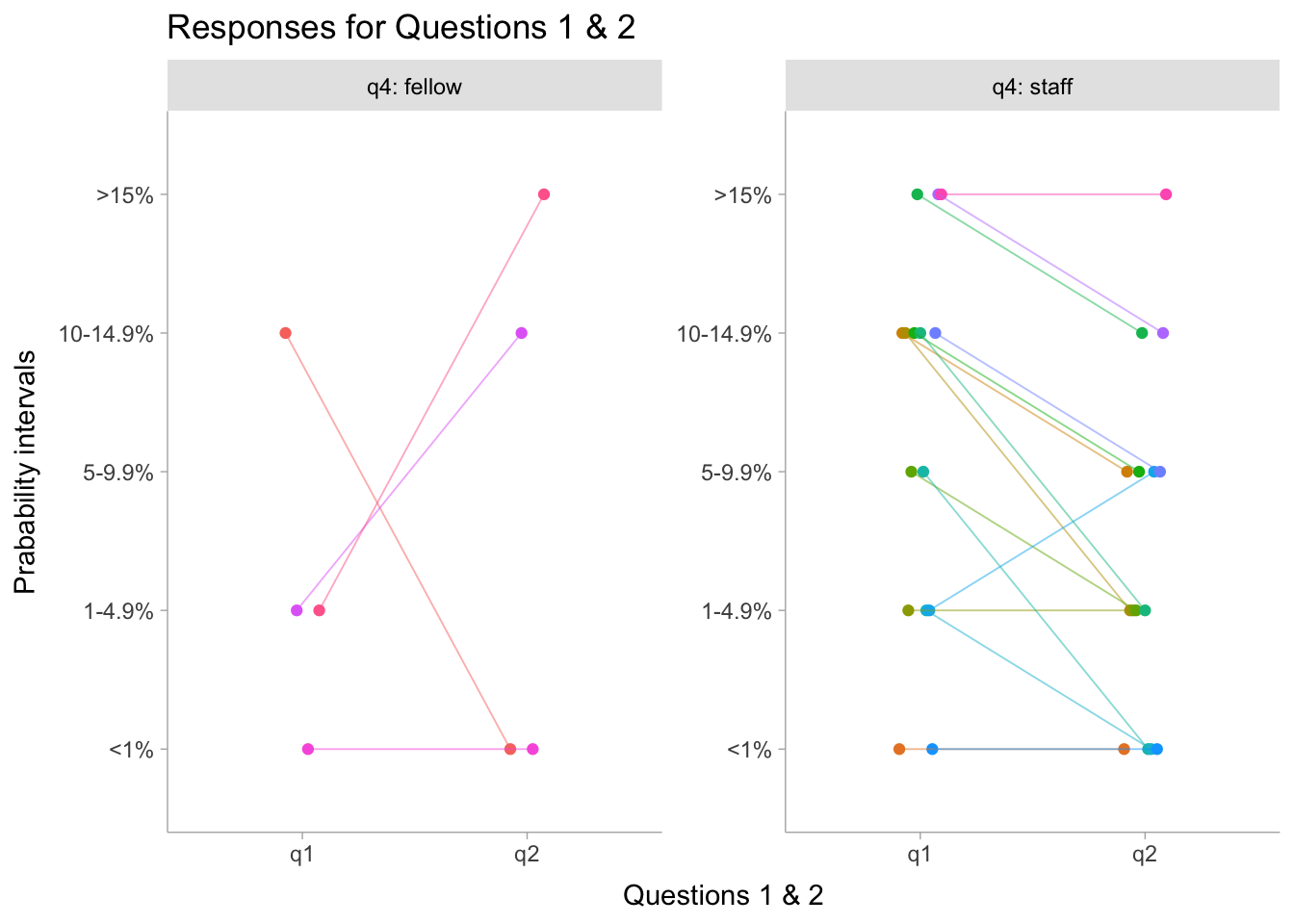
Quiz Results
I received replies from 15 (42%, n= 36) MUHC cardiology staff and 4 (18%, n = 22) fellows with the following results
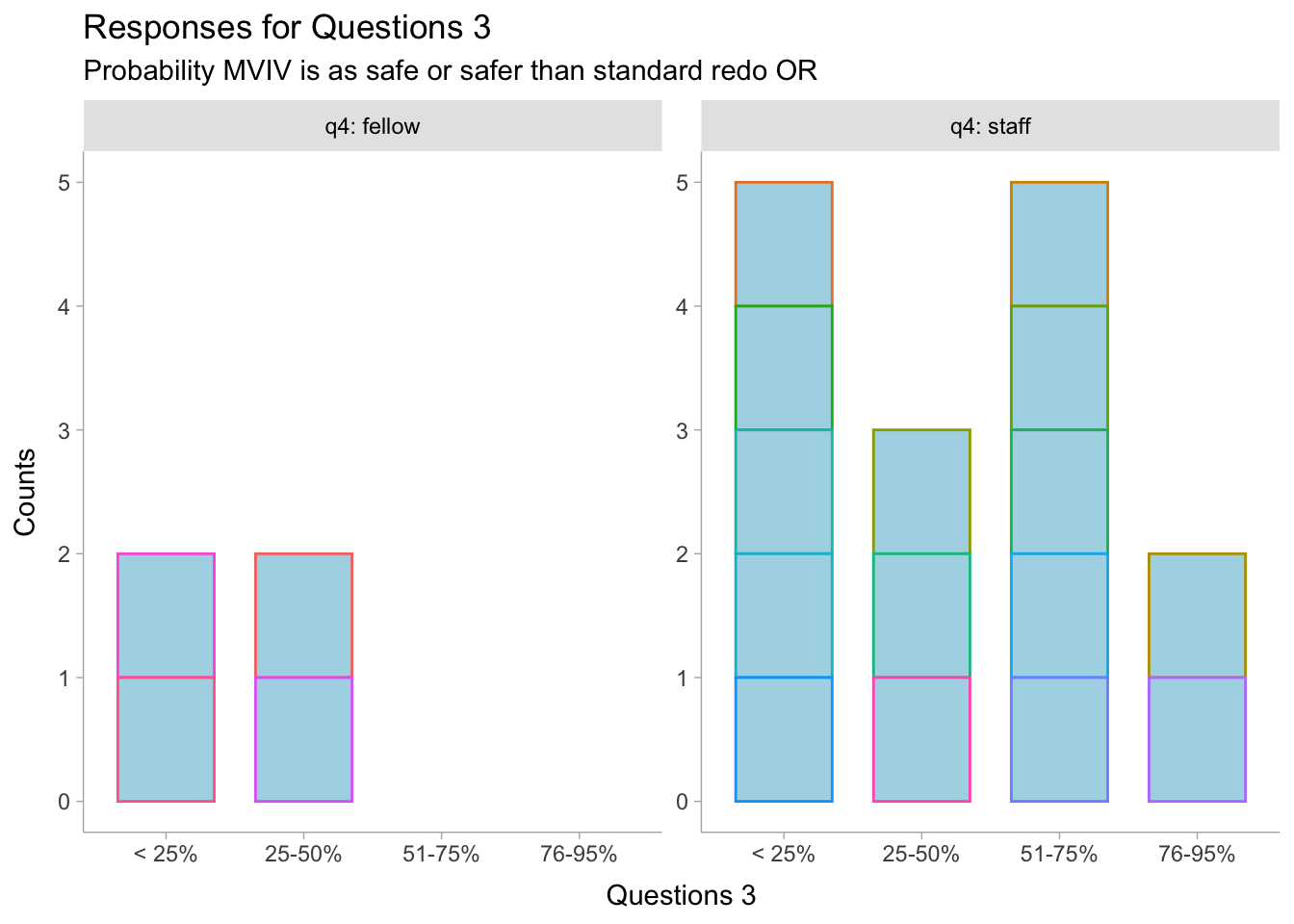
dat2<-read.csv("results1.csv", header =T)|>mutate(id=factor(id), q3 =factor(q3))dat2%>%mutate(value =fct_relevel(q3, "< 25%", "25-50%", "51-75%", "76-95%"))|>ggplot(aes(x =q3, group =id, color=id))+geom_bar(stat="count", width=0.7, fill="lightblue")+guides(color =FALSE)+facet_wrap(~q4, labeller =label_both, axes ="all_y")+xlab("Questions 3")+ylab("Counts")+labs(title ="Responses for Questions 3", subtitle ="Probability MVIV is as safe or safer than standard redo OR")+theme_ggdist()
Warning: The `<scale>` argument of `guides()` cannot be `FALSE`. Use "none" instead as
of ggplot2 3.3.4.
Quiz Answers
To appreciate the uncertainty associated with observing 0 deaths in 50 patients if the expected rate was 4%, one can use either a Poisson distribution (counts) or a binomial distribution (independent Bernouilli trials) where each of the 50 subjects is considered as alive or dead with a probability of 4%. These calculations can be done with the above equations or more easily with any software that includes Poisson or Binomial distributions.
Q1. If mortality rates with transcatheter MVIV are assumed the same as with a standard redo, what is the probability of observing 0 deaths asthese authors did?
Code
options(digits=1)# calculate the probability of 0 to 6 deaths among 50 patients with an expected rate of 4%# binomial distributiondb<-100*dbinom(c(0:8),50, .04)# expected 4% probability of death# Poisson distributiondp<-100*dpois(c(0:8),2)# number of expected deaths among the 50 subjects over 1 year# cat("Assuming a binomial distribution with an event (death) # probability of 4%, the probability for 0,1,2,3,4,5,6 events is ", # db[1],"%,", db[2],"%,", db[3],"%,", db[4],"%,", db[5],"%,", # db[6],"%, respectively")#cat("\nAssuming a Poisson distribution with an event (death) rate of # 2 (2 deaths / 50 individual in 1 year, 4% expected mortality), the # probability for 0,1,2,3,4,5,6 events is ", dp[1],"%,", dp[2],"%,", # dp[3],"%,", dp[4],"%,", dp[5],"%,", dp[6],"%, respectively")
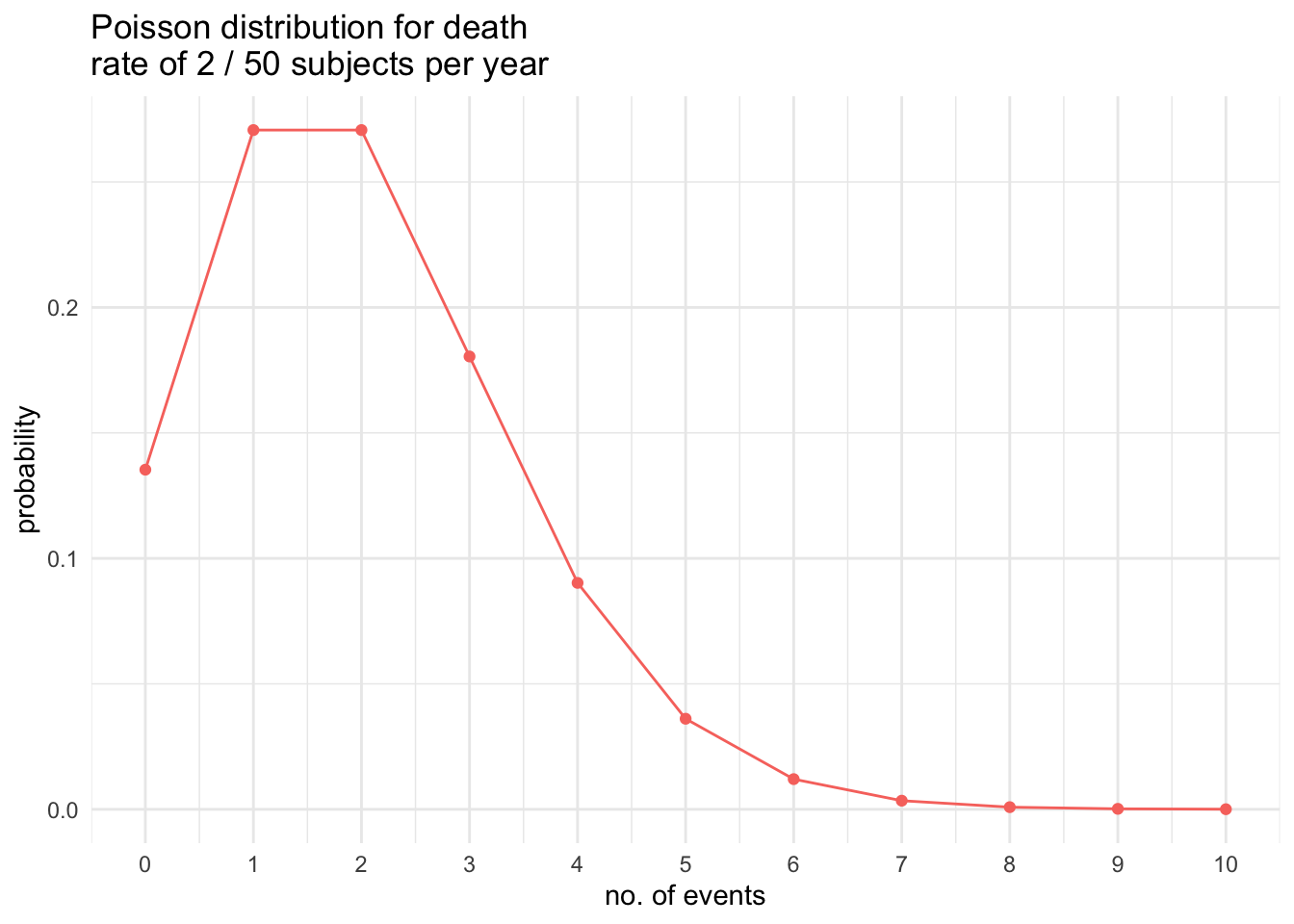
Assuming a binomial distribution with an event (death) probability of 4%, the probability for 0, 1, 2, 3, 4, 5, 6 events is 13%, 27.1%, 27.6%, 18.4%, 9%, 3.5%, respectively.
Assuming a Poisson distribution with an event (death) rate of 2 (# deaths in 50 individual in 1 year with 4% expected mortality), the probability for 0, 1, 2, 3, 4, 5, 6 events is 13.5%, 27.1%, 27.1%, 18%, 9%, 3.6%, respectively.
This data can also be visualized as shown here
Code
# Build Poisson distributionsoptions(digits =3)p_dat<-map_df(2, ~tibble( l =paste(.), x =0:10, y =dpois(0:10, .)))# Use ggplot2 to plotggplot(p_dat, aes(x, y, color =factor(l, levels =1:5)))+geom_line()+geom_point(data =p_dat, aes(x, y, color =factor(l, levels =1:5)))+labs(color ="Lambda:")+ggtitle("Poisson distribution for death \nrate of 2 / 50 subjects per year")+scale_x_continuous("no. of events",breaks=seq(0,10, 1))+ylab("probability")+theme_minimal()+theme(legend.position="none")
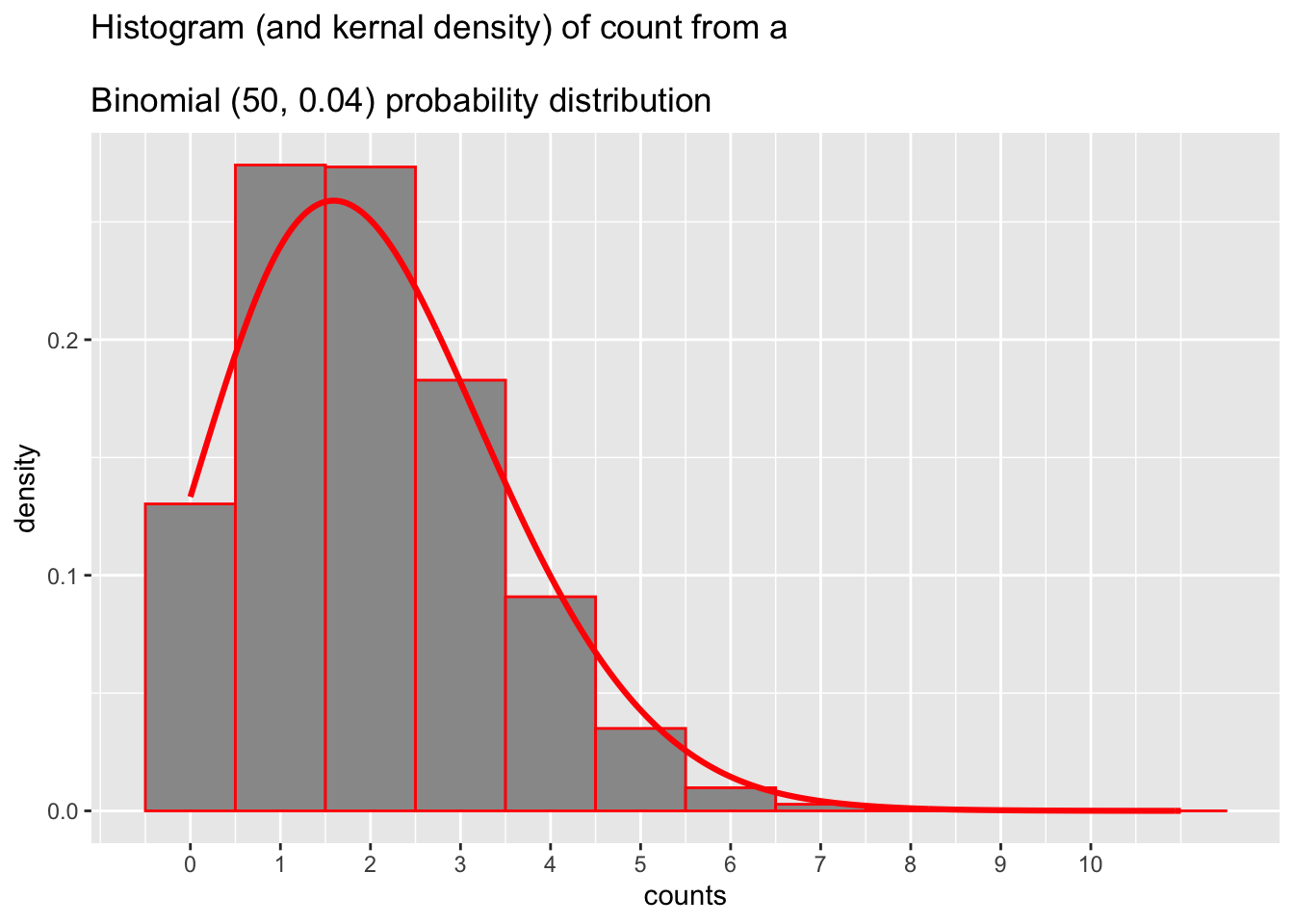
The similarity between the Poisson and Binomial distributions is shown graphically below
Code
options(digits=2)df<-data.frame(y=round(rbinom(50000,50,.04)))g=ggplot(df, aes(x=y))# g + geom_histogram(binwidth=1, fill="grey60", color="red") # counts# g + geom_histogram(aes(y=after_stat(density)), binwidth=1, fill="grey60", color="red") # densityg+geom_histogram(aes(y=after_stat(density)), binwidth=1, # density fill="grey60", color="red")+geom_density(adjust=5, color="red", size=1.1)+xlab("counts")+scale_x_continuous(breaks =seq(0, 10, by =1))+ggtitle("Histogram (and kernal density) of count from a \nBinomial (50, 0.04) probability distribution")
Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` instead.
Code
# same code for Poisson# df1 <- data.frame(y=round(rpois(50000,2)))
Therefore the answer to Q1 is 10 - 14.9%
Q2. If mortality rates with transcatheter MVIV were actually 40% higher those with a standard redo, what is the probability of observing 0 deaths as these authors did?
In other words what is the probability of observing 0 deaths if the expected rate was 5.6% (4*1.4).
Code
options(digits=1)# calculate the probability of 0 to 6 deaths among 50 patients with an expected rate of 4%# binomial distributiondb1<-100*dbinom(c(0:8),50, .056)# expected 4% probability of death# Poisson distributiondp1<-100*dpois(c(0:8),2.8)# number of expected deaths among the 50 subjects over 1 year
Assuming a binomial distribution with an event (death) probability of 5.6%, the probability for 0, 1, 2, 3, 4, 5, 6 events is 5.6%, 16.6%, 24.2%, 22.9%, 16%, 8.7%, respectively.
Assuming a Poisson distribution with an event (death) rate of 2.8 (# deaths in 50 individual in 1 year with 5.6% expected mortality), the probability for 0, 1, 2, 3, 4, 5, 6 events is 6.1%, 17%, 23.8%, 22.2%, 15.6%, 8.7%, respectively.
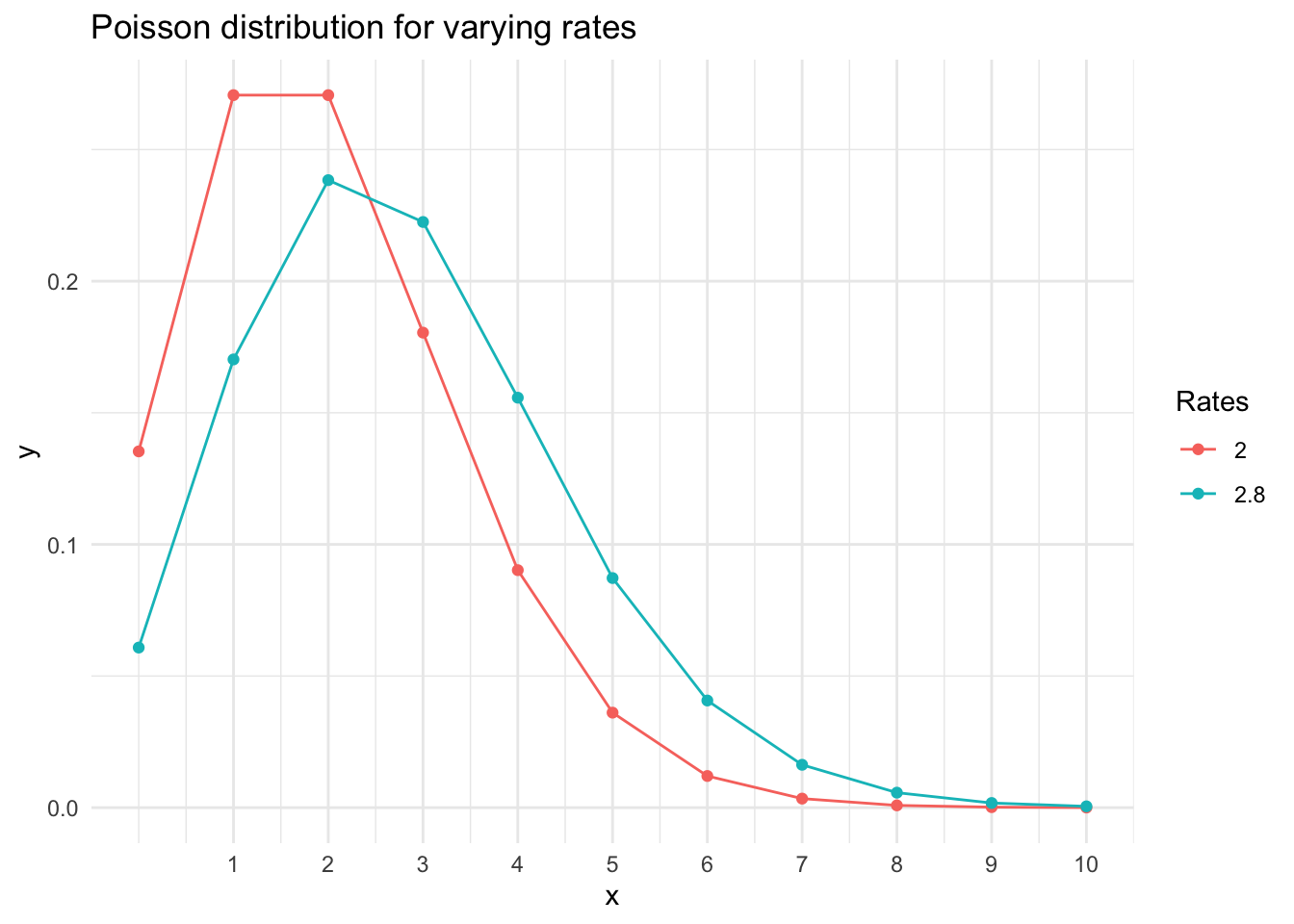
This may be easier to appreciate visually
Code
p_dat<-map_df(c(2,2.8), ~tibble( l =paste(.), x =0:10, y =dpois(0:10, .)))# Use ggplot2 to plotggplot(p_dat, aes(x, y, color =factor(l, levels =c(2,2.8))))+geom_line()+geom_point(data =p_dat, aes(x, y, color =factor(l, levels =c(2,2.8))))+labs(color ="Rates")+ggtitle("Poisson distribution for varying rates")+scale_x_continuous(breaks =c(1:10), limits =c(0, 10))+theme_minimal()
Clearly, if the expected death rate is higher the curves shift left meaning the probability of observing 0 deaths will fall with increasing mortality rates, so The answer to Q2 is 5 - 9.9%
Q3. Given the above information (and that there is probably not a lot of other of good quality available evidence), what is your probability (belief) that MVIV is as safe or safer than a standard redo operation in this population?
Iideally one would like to know the outcome with both interventions in the same patient but such counterfactuals unfortunately don’t exist. As an alternative we perform randomized trials, where we hope that subjects in the two treatment arms are exchangeable. In this case, we lack a proper comparative arm but can assume that if the STS model is accurate and that the MVIV patients would have had a 4% mortality if instead of MVIV they had had a surgical redo. Therefore our data are the 50 observed MVIV results and 50 results under a redo operation with a 4% mortality rate.
Code
# create data framedat1<-tibble(Trial =c("study", "study"), Tx =c("redo", "MVIV"), fail =c(2, 0), success =c(48,50))%>%mutate(total =fail+success, prop_success =success/total)fit4<-brm(success|trials(total)~Tx, data =dat1, iter =10000, family =binomial(link="identity"), refresh=0, control =list(adapt_delta =.999), backend ="cmdstanr", seed =123, file ="fit4.RDS")#aggregate data
Warning: There were 15936 divergent transitions after warmup. Increasing
adapt_delta above 0.999 may help. See
http://mc-stan.org/misc/warnings.html#divergent-transitions-after-warmup
Family: binomial
Links: mu = identity
Formula: success | trials(total) ~ Tx
Data: dat1 (Number of observations: 2)
Draws: 4 chains, each with iter = 10000; warmup = 5000; thin = 1;
total post-warmup draws = 20000
Regression Coefficients:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
Intercept 0.98 0.02 0.93 1.00 1.00 1229 2480
Txredo -0.04 0.04 -0.13 0.03 1.01 703 521
Draws were sampled using sample(hmc). For each parameter, Bulk_ESS
and Tail_ESS are effective sample size measures, and Rhat is the potential
scale reduction factor on split chains (at convergence, Rhat = 1).
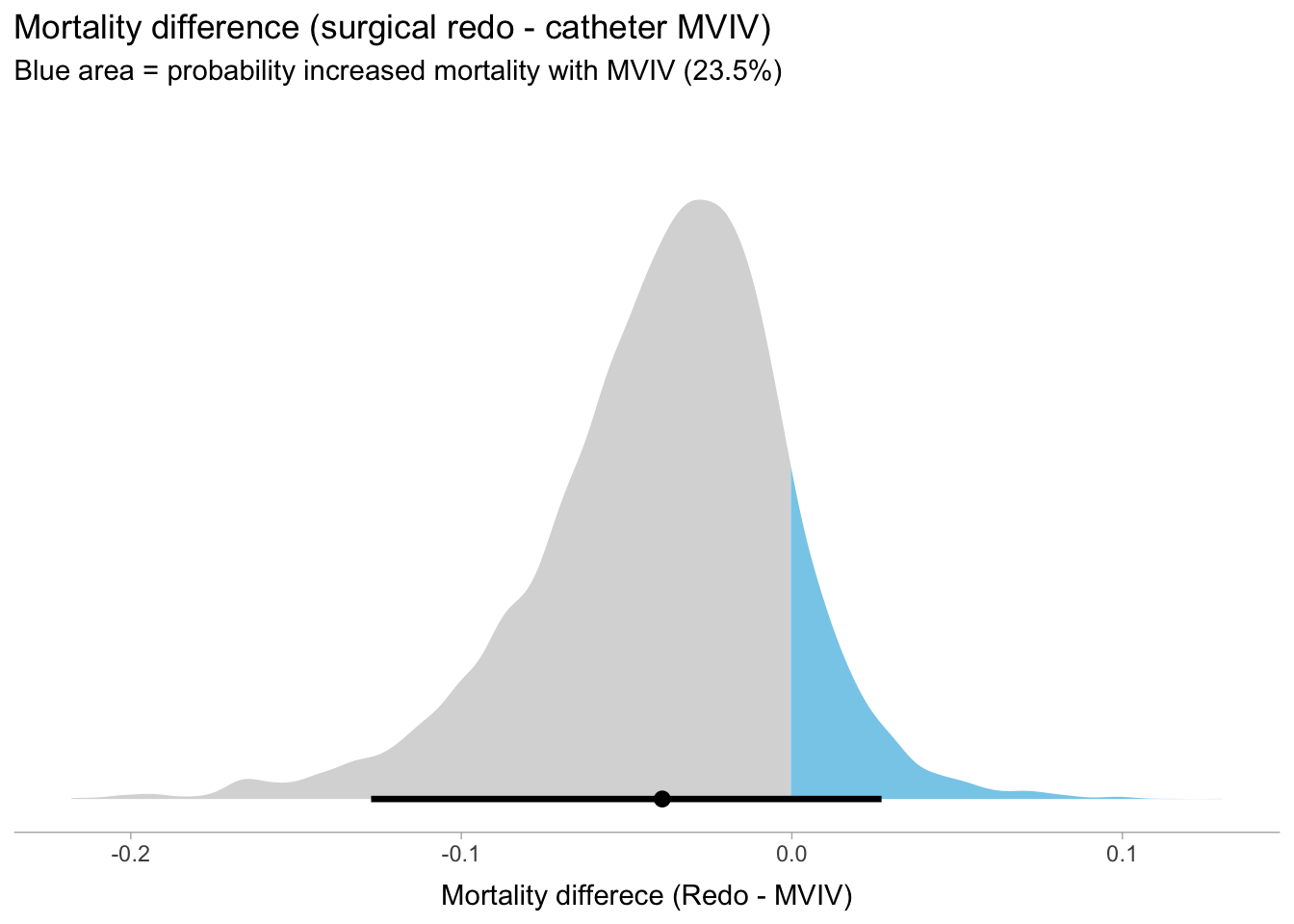
As expected the mean mortality difference (MVIV - redo) is - 4% with 95% credible intervals -13% -to 3% This probability density for this mortality difference is shown graphically below
Code
draws<-as_draws_df(fit4)p_gt_0<-sum(draws$b_Txredo>0)/20000draws%>%ggplot(aes(x =b_Txredo, fill =stat(x>0)))+stat_halfeye(point_interval =mean_qi, .width =.95)+scale_fill_manual(values =c("gray85", "skyblue"))+scale_y_continuous(NULL, breaks =NULL)+xlab("Mortality differece (Redo - MVIV)")+labs(title ="Mortality difference (surgical redo - catheter MVIV)", subtitle ="Blue area = probability increased mortality with MVIV (23.5%)")+theme_ggdist()+theme(legend.position ="none")
Warning: `stat(x > 0)` was deprecated in ggplot2 3.4.0.
ℹ Please use `after_stat(x > 0)` instead.
This figure shows that there is a 11.7% probability that MVIV patients in this study would have a worse outcome with a surgical redo, provided their underlying mortality has been well predicted with the STS model. Alternatively, the probability that MVIV is as safe or safer than a redo is 88.3%. Therefore the answer to Q3 is 76-95%
Discussion
For Q1, only 3 people (16%) correctly estimated that there was a 10-14.9% probability of observing 0 deaths in 50 patients, if the true underlying mortality rate was 4%. Of the 16 respondents who incorrectly estimated the probability, most (13 of 16) underestimated the probability of observing 0 deaths.
For Q2, most respondents (13/19, 68%) correctly reasoned that if the true underlying mortality increased, it would be more unlikely to observe 0 deaths. However 6 individuals didn’t appreciate this and incorrectly predicted no change or an increase in the probability of observing 0 deaths if the true underlying rate was higher.
For Q3, there are many assumptions required and estimates are likely fairly unreliable. Nevertheless, the question asked to ignore the potential biases and to consider only the data in this one study. Only 2 (10.5%) of individuals correctly estimated the probability of MVIV being as safe or safer than a redo being in the 76-95% interval. 12 of 19 (63%) of respondents estimated this probability at being under 50%.
Drawing meaningful conclusions is obviously limited by the limited number of respondents, especially among the fellows. It is unknown if respondents have better, worse or same quantitative skills as the non-respondents. Notwithstanding this limitation, it would appear from the wide range of responses and the limited number of “correct” answers that additional quantitative training may be helpful.
References
Malaisrie, S. Chris, Mayra Guerrero, Charles Davidson, Mathew Williams, Fábio Sândoli de Brito, Alexandre Abizaid, Pinak Shah, et al. 2024. “One-Year Outcomes of Transseptal Mitral Valve-in-Valve in Intermediate Surgical Risk Patients.”Circulation: Cardiovascular Interventions 17 (8): e013782. https://doi.org/10.1161/CIRCINTERVENTIONS.123.013782.
Citation
BibTeX citation:
@online{brophy2024,
author = {Brophy, Jay},
title = {Estimating {Uncertainty}},
date = {2024-09-14},
url = {https://brophyj.github.io/posts/2024-09-14-my-blog-post/},
langid = {en}
}